
Over the summer of 2016 I created a Pine64 cluster for Embecosm, for use with their work on the TSERO project.
To begin with I had a cluster of four boards and I used Linpack to benchmark my original quartet: their highest result was 5.7GFlops, which would have put them on the top500 until 1997. The version of Linpack I used is HPL (High-Performance Linpack) and I attempted no optimisation.
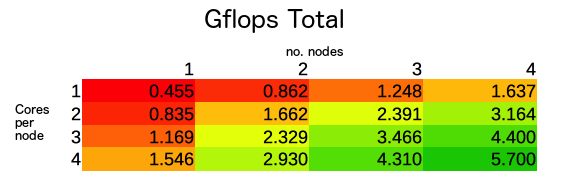
Originally I only had 4 boards and we wanted to have 64 cores in total, so we bought 12 more. In the meantime I decided to benchmark every configuration possible. I tested from 1 board running 1 core, to 4 boards running across 4 cores with each. I got the following results:
Next I decided to compare the GFlops per core in use, to see which configuration gets the most from each core:
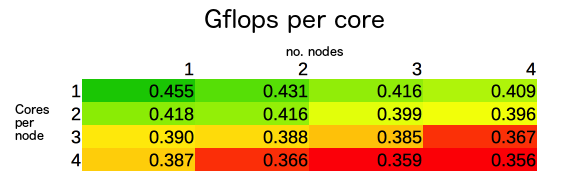
It turns out there were strange patterns starting to emerge. For example, it seemed that using as many boards as possible was always the best solution for optimal total GFlops and therefore Gflops per core.
However, if we were to only use a maximum of 4 cores, we would’ve predicted that using 4 boards would have been best — but this is wrong and the best way to run 4 cores would be to have 2 boards each running 2 cores, for an increase of 7.5% from 1 board with 4 cores.
From plotting these results I extrapolated an estimate for the future 64 cores, I predicted that the total cluster would achieve 22.5Gflops.
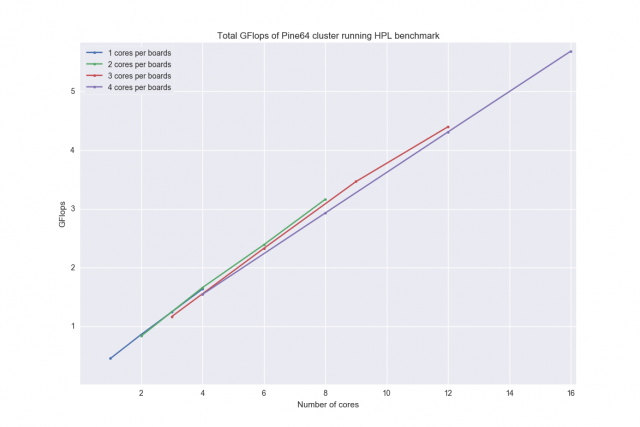
Unfortunately the peak Gflops from the full cluster of 16 boards was only 20GFlops, which suggests that the scaling is not as linear as we believed it would be. However, to run Linapck on all 16 boards took 3 hours, therefore when running the benchmarks they took longer than an extended weekend. In order to get results that I could start to play around with, we shortened the amount of memory given to each node from 1750MB to 50MB. This made the iterations run in a couple minutes each. So although the results are not the best, they should show a similar relationship to the optimum results.
I ran each iteration 3 times and averaged. Plotting the data:
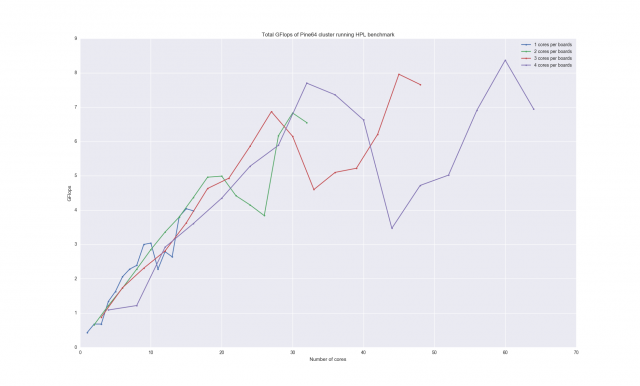
I re-ran some of the programs from Pine16 after the first run produced awful results. However some still did not improve, so I left the original. I’m very skeptical of the later half of the each group’s iterations. On the other hand we would expect the rate of performance increase to decrease, as we increase the communication needed. They were run in order of amount of boards, so 14 boards using 3 cores each was followed by 14 boards with 2 cores each, which might also explain why each line follows a similar path.
For almost all runs of up to 10 cores the single core per board line is above the rest. This trend carries on after 10 cores, with 2 cores per board taking over from 20 cores until 30 cores. The pattern roughly continues again with 3 cores per board and with 4.
We can almost start to see how the line is becoming non-linear, but only just.
To measure energy data I recorded the power at random points throughout each benchmark and averaged. I then plotted the results, which included the switch in the power measurement:
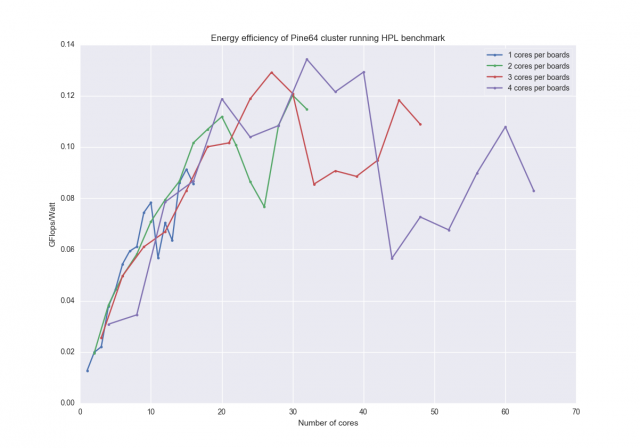
With this the pattern is less visible and this might be because of the noise in the results, but we can see that for their respective sections the cores per board are the most efficient until 40 cores.
An odd thing happens at 30 cores in both graphs: all 3 lines almost join, It’s also very interesting that every line takes a similar path, following the same pattern.
In conclusion we can see that after 8 boards results become very unpredictable, therefore in the future to investigate this we might be able to measure communication between the boards, or the CPU usage to see if the processor ever goes idle. We could also adjust the size of the matrix used when testing for 9 boards, in order to find out what’s happening.
Although I don’t have a nice linear graph showing perfect scaling — instead erratic data after the 30 cores mark — it shows how benchmarking is a difficult process and that at least with up-to 8 boards, we see predictable scaling.
Even if the benchmarking results do appear sub-optimal, I found it really fun analysing the data and then finding ways to present the data.