
Security of networked computers has been important for a long time, particularly for large facilities. However it is becoming increasingly important as powerful computing engines are incorporated into the most mundane of everyday objects.
The original Carnegie-Mellon University CERT Co-ordination Centre dates from 1998. Organizations such as the NSA and GCHQ — and their equivalents in other countries — are concerned about computer security from a national perspective. Conversely, individual citizens may be concerned about the security of their own computing facilities from such organizations. While large companies are concerned about security of centralized facilities such as data centers. At the much smaller scale, security is central to smart bank cards, travel cards and the like.
 The step change in recent years has been the emergence of the Internet of Things. When we heard of a hacked Internet connected toilet, we may have smiled. When we heard how easy it was to hack an Internet connected light bulb, we may started to worry. But it was the emergence of the Mirai botnet, and in particular the DDOS attack of 21 October 2016, which alerted the world to just some of the problems posed by huge numbers of insecure devices connected to the Internet.
The step change in recent years has been the emergence of the Internet of Things. When we heard of a hacked Internet connected toilet, we may have smiled. When we heard how easy it was to hack an Internet connected light bulb, we may started to worry. But it was the emergence of the Mirai botnet, and in particular the DDOS attack of 21 October 2016, which alerted the world to just some of the problems posed by huge numbers of insecure devices connected to the Internet.
Why the compiler?
Computer security is a system wide challenge. It only takes one part of a system to be insecure and the whole system becomes insecure. A compiler cannot magically fix insecure code, but it is perfectly placed to help the professional software engineer write secure systems. The reason is that the compiler is the one program that gets to look at (almost) every line of software. Obviously compiled languages such as C/C++ go through the compiler. But semi-interpreted languages such as Java also need a compiler to generate their bytecode and even assembler code is typically pre-processed by the compiler. The only exceptions are purely interpreted scripting languages and computer conservationists entering hex machine code into legacy hardware.
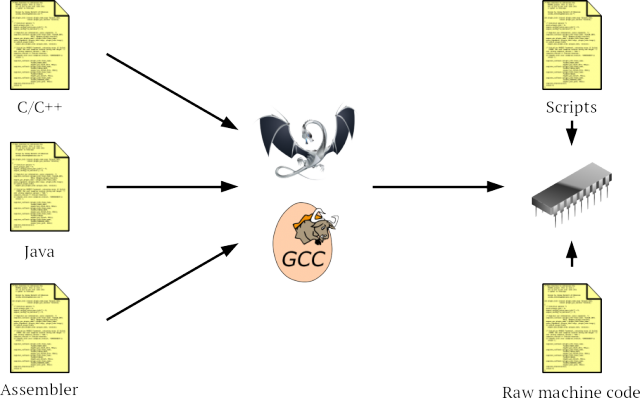
How can the compiler help in general?
There are two general ways the compiler can help.
- Warning of bad practice. Advising the programmer when code appears to follow bad practice
- Providing heavy lifting. Automating complex tasks to make them easier for the programmer.
Target specific compiler help
There is also more specialist support possible from the compiler. My colleague, Simon Cook, spoke on Using LLVM to guarantee program integrity at the LLVM Developer Meeting in November 2106. His talk explained how the compiler can be used to support specialist processor hardware for security. In this case, where the hardware adds support for instruction and control flow integrity. The outcome was a compiler with a new protected attribute which can be applied to functions taking advantage of the hardware security features. Since Simon covered this subject so well, I will not talk further about it in this post.
A simple example
Consider the following program:
int mangle (uint32_t k) { uint32_t res = 0; int i; for (i = 0; i < 8; i++) { uint32_t b = k >> (i * 4) & 0xf; res |= b << ((7 - i) * 4); } return res; } int main (int argc, char *argv[]) { uint32_t km; km = mangle (atoi (argv[1])); return (&km)[2]; }
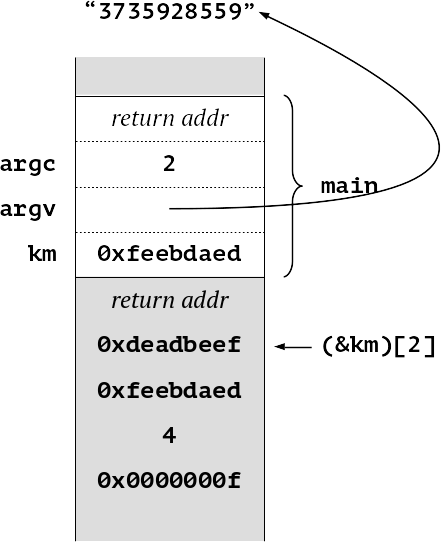
A trivial program to receive a key on the command line, then transform it into a more secure form for internal use (in this case trivially reversing the nybbles). Once the function mangle has completed, it might be thought that the original key is safely converted. However, let us look at the stack as this program executes. First of all at the start of main ()
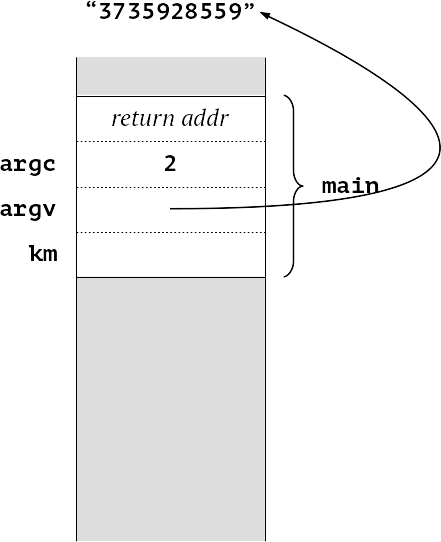
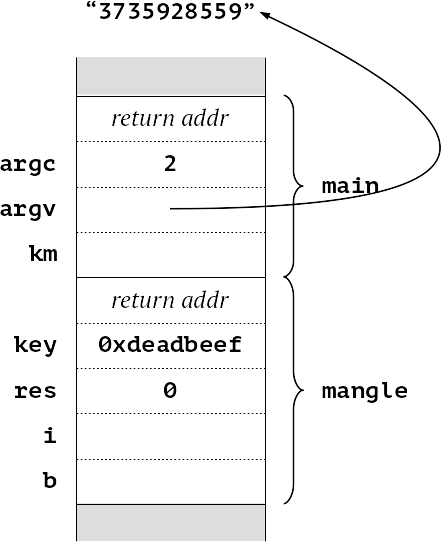
We have our number of arguments on the stack, and a pointer to the command line (strictly speaking argv[1]). As we enter mangle, we can see the argument srtring “3735928599” has been read, converted to a number (0xdeadbeef) and appears on the stack, along with the initial value of res, 0.
When we return we can see that the value of km has been correctly computed as 0xfeebdaed.
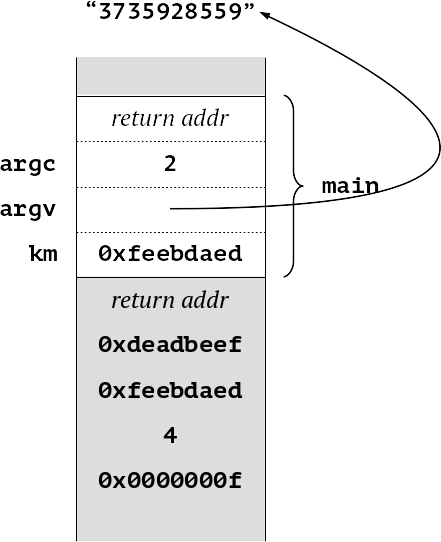
The problem is that we have left our original value lying on the stack. So a malicious program can potentially access it—in this example as (&km)[2].
The compiler can easily act as an assistant to the programmer. We have created a new attribute, erase_stack, which clears all the values from the stack (and indeed the registers on return).
int mangle (uint32_t k)__attribute__ ((erase_stack)) { uint32_t res = 0; int i; for (i = 0; i < 8; i++) { uint32_t b = k >> (i * 4) & 0xf; res |= b << ((7 - i) * 4); } return res; } int main (int argc, char *argv[]) { uint32_t km; km = mangle (atoi (argv[1])); return (&km)[2]; }
We can easily extent this to erase to a specific value, rather than zero.
int mangle (uint32_t k)__attribute__ ((erase_stack (0xaa))) { uint32_t res = 0; int i; for (i = 0; i < 8; i++) { uint32_t b = k >> (i * 4) & 0xf; res |= b << ((7 - i) * 4); } return res; } int main (int argc, char *argv[]) { uint32_t km; km = mangle (atoi (argv[1])); return (&km)[2]; }
We can also provide a variant to erase the stack to a random value.
int mangle (uint32_t k)__attribute__ ((radnomize_stack)) { uint32_t res = 0; int i; for (i = 0; i < 8; i++) { uint32_t b = k >> (i * 4) & 0xf; res |= b << ((7 - i) * 4); } return res; } int main (int argc, char *argv[]) { uint32_t km; km = mangle (atoi (argv[1])); return (&km)[2]; }
A slightly more complex problem is values left lying in memory when using setjmp/longjmp. For example, a program with the following structure:
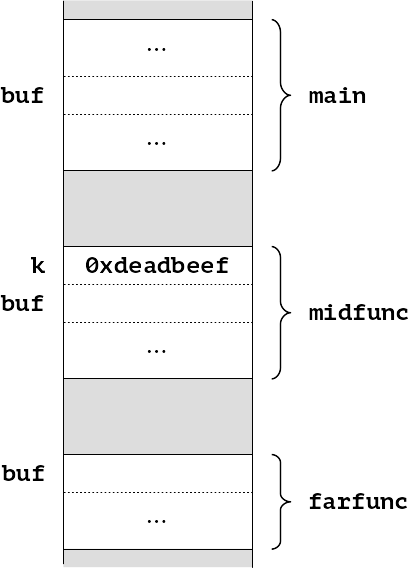
int main () { ... setjmp (buf) ... } int midfunc (uint32_t k, jmp_buf *buf) { ... } int farfunc (jmp_buf *buf) { ... longjmp (*buf, 42); }
The stack as we enter farfunc, might look something like this.
When we execute the longjmp, control returns to main and we see the problem.
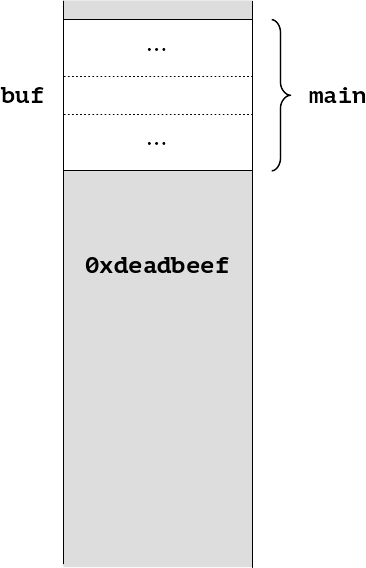
We have left the value of k from midfunc lying in memory. No amount of erase_stack attributes can help us here, because setjmp does not typically unwind the stack function by function. However, it does know where it starts and finishes, so there is no reason why the stack cannot be erased. Instead we need a program wide option.
clang -ferase-stack ... gcc -ferase-stack ...
And our stack will then be erased, whether an ordinary function return or through longjmp:
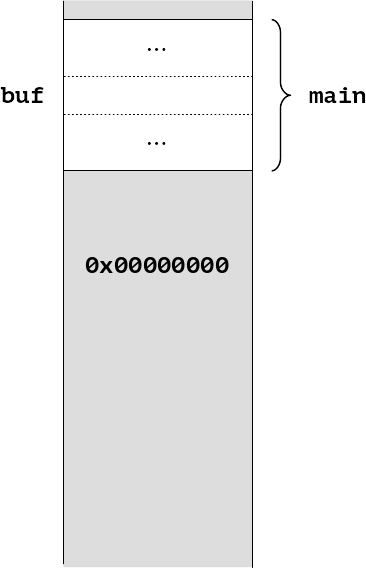
Similarly, we can ask for the stack to be erased to a particular value.
clang -ferase-stack=0xaa ... gcc -ferase-stack=0xaa ...
Our stack will then be erased to this value, whether an ordinary function return or through longjmp:

Finally, we can ask for the stack always to be erased to random values:
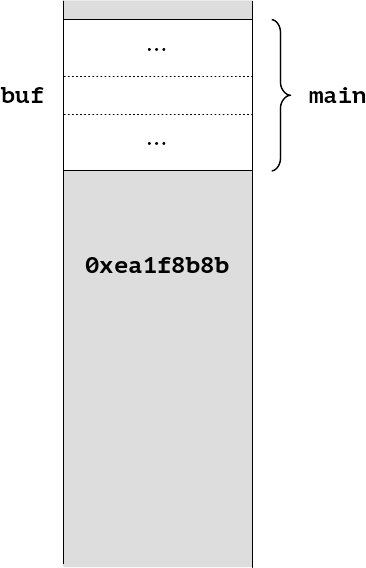
This is a problem for which Embecosm have already provided an LLVM implementation to one customer, and which in due course we will be offering upstream. In summary we provide new function attributes to provide control of stack erasure for individual functions.
__attribute__ ((erase_stack)) __attribute__ ((erase_stack (n))) __attribute__ ((randomize_stack))
And we provide command line options to provide erasure for all functions in a program, including longjmp.
clang | gcc -ferase-stack … clang | gcc -ferase-stack=n … clang | gcc -frandomize-stack …
A slightly harder problem
Consider the following program.
#include <stdint.h> #include <stdio.h> #include <stdlib.h> int globvar; int main (int argc, char *argv[]) { uint32_t k, km; k = atoi (argv[1]); globvar = 1729; km = (k * k) % globvar; if (globvar != 1729) printf ("Globvar wrong\n"); return km; }
It seems fairly obvious that the test for globvar being equal to 1729 is entirely redundant. We set it two instructions before, it isn’t volatile and nothing has changed it. Without optimization we would get:
… callq atoi movl %eax, -20(%rbp) movl $1729, globvar movl -20(%rbp), %eax imull -20(%rbp), %eax xorl %edx, %edx divl globvar movl %edx, -24(%rbp) cmpl $1729, globvar je .LBB0_2 movabsq $.L.str, %rdi movb $0, %al callq printf movl %eax, -28(%rbp) .LBB0_2: movl -24(%rbp), %eax addq $32, %rsp popq %rbp retq
But with any optimization, the test and branch is removed, since it is redundant:
… callq strtol movl $1729, globvar(%rip) imull %eax, %eax imulq $792420225, %rax, %rcx shrq $32, %rcx movl %eax, %edx subl %ecx, %edx shrl %edx addl %ecx, %edx shrl $10, %edx imull $1729, %edx, %ecx subl %ecx, %eax popq %rcx retq
So why did the programmer write this? One way to attack a program is to take the top off a chip and shine a very bright light at it, in the hope of flipping a few bits. This code is a defense against this happening when making the important calculation:
km = (k * k) % globvar;
The test is that the value of globvar hasn’t been changed by a laser light during the calculation. One way to preserve the calculation is to declare globvar volatile.
volatile int globvar;
The problem with this is that now all uses of globvar will be immune to optimization, while we may only care about this one particular case. I talked about this at FOSDEM 2017, and a suggestion from the audience was to use something like the Linux kernel ACCESS_ONCE macro, which provides a temporary cast to volatile of a key variable. This is something for us to explore for the future.
The LADA project
Embecosm are the industrial supporter of the EPSRC funded academic research project, Leakage Aware Design Automation, being led by Prof Elisabeth Oswald and Dr Dan Page at the University of Bristol. This is a four year program supported by a team of research associates and PhD students to explore the very latest ideas in designing computers to be resistant to attack. The compiler is one of the major tools they will be investigating. As industrial supporter, Embecosm will be writing open source implementations of the research concepts for GCC and LLVM, to prove that they can be transferred to the real world (or possibly not!). To drive this work we’ll be providing PhD internships to students on the program. This project is still at a relatively early stage, so much of what I describe in this blog is about the future. It also means that there is still the opportunity to apply for some of the posts at the University of Bristol.
Elisabeth Oswald wrote a guest blog post on the project last year, which provides more information about LADA and how you can get involved.
What is information leakage?
Wikipedia provides a useful definition:
“Information leakage happens whenever a system that is designed to be closed to an eavesdropper reveals some information to unauthorized parties nonetheless.”
An example (also Wikipedia) comes from the second world war, where the Japanese high command were communicating to their warships by radio, using encryption that the American’s had yet to crack. However, the Americans noticed that the outcome of such transmissions depended on which land station sent the signal, and from that they could glean some information.
Power analysis
One widely used way of attacking computer systems is to look at how much energy they use when carrying out computations, a technique called power analysis. Most useful is to look at how the power usage varies when different inputs are supplied, a technique know as differential power analysis.
Consider the following program.
int func (uint32_t k) { int i, res = 0; for (i = 0; i < 10000000; i++) if (1 == (k & 1)) res += k - 1; else { double r; r = sqrt ((double) k); res += (int) r; } return res; } int main (int argc, char *argv[]) { return func (atoi (argv[1])); }
I can run this on my laptop, and, using time run as a proxy for energy consumed I find the following:
$ time ./dpa 7 real 0m0.025s user 0m0.024s sys 0m0.000s
and
$ time ./dpa 6 real 0m0.086s user 0m0.084s sys 0m0.000s
Indeed if I ran with many different values, I would quickly deduce that this program does a lot more computation for odd numbered values than even numbered, and hence know a tiny bit about how my algorithm works. The problem is in the 6th line of func.
int func (uint32_t k) { int i, res = 0; for (i = 0; i < 10000000; i++) if (1 == (k & 1)) res += k - 1; else { double r; r = sqrt ((double) k); res += (int) r; } return res; }
A critical variable, k, is being used to control the flow of the program and hence how much computation is being done. This leads to information leakage. Any professional software engineer knows that secure code should never be flow dependent on critical variables, but in a large program, even professionals can miss such behavior, particularly if it is caused by an alias in a function a long way away. Indeed, it is not just control flow, but data dependent instruction timing and data dependent memory access that can cause problems — both considerably harder for the software engineer to see and control.
Warning about critical variables
As I noted at the top of this post, one of the roles the compiler can take is to warn about critical variables being used to control flow. This is one feature we have planned to implement as part of our contribution to the LADA project. We would like to give any critical variable an attribute, to tell the compiler to watch it (and its aliases) and warn of dangerous code. For example.
int func (uint32_t k __attribute__ ((critvar)) { int i, res = 0; if (1 == (k & 1)) res += k - 1; else { double r; r = sqrt ((double) k); res += (int) r; } return res; }
The compiler can then warn:
$ clang -c gv.c gv.c:6:12: warning: critical variable controlling flow 'k' [-Wcritical-variable] if (1 == (k & 1)) ^
And it also works simply enough for global variables
myinc.h: extern uint32_t k __attribute__ ((critvar)); gv.c: #include "myinc.h" int func () { int i, res = 0; if (1 == (k & 1)) res += k - 1; else { double r; r = sqrt ((double) k); res += (int) r; } return res; }
We get the same warning
$ gcc -c gv.c gv.c:6:12: warning: critical variable controlling flow 'k' [-Wcritical-variable] if (1 == (k & 1)) ^
In both these cases critical variable usage is obvious.
Indirect critical variables
So far we have considered critical variables directly controlling flow. But we also need to consider derived expressions:
int func (uint32_t k __attribute__ ((critvar))) { int i, res = 0; uint8_t b = k & 0xff; if (1 == (b & 1)) res += k - 1; else { double r; r = sqrt ((double) k); res += (int) r; } return res; }
In this case it is not k controlling the flow, but an expression using k. We still want to see the error message:
$ clang -c gv.c gv.c:6:12: warning: critical variable controlling flow 'b' [-Wcritical-variable] if (1 == (b & 1)) ^
We can only achieve this by understanding the local dataflow within the function.
Critical variables spanning functions
Consider the following two source files, gv1.c:
int func1 (uint32_t k __attribute__ ((critvar))) { return func2 (k); }
and gv2.c:
int func2 (uint32_t x) { int i, res = 0; if (1 == (x & 1)) res += x - 1; else { double r; r = sqrt ((double) x); res += (int) r; } return res; }
If we compile and link these, we will see no warning.
$ gcc -c gv1.c $ gcc -c gv2.c $ gcc gv1.o gv2.o $
Now one option would be to mark x in func2 as having the critvar attribute. But that would then consider all use cases, even ones where func2 is not being used for critical variables. The solution is to take a whole program view.
$ gcc -flto -c gv1.c $ gcc -flto -c gv2.c $ gcc -flto gv1.o gv2.o gv2.c:5:12: warning: critical variable controlling flow 'x' [-Wcritical-variable] if (1 == (x & 1)) ^
We need to look at the global dataflow, to work out that x is being used as a critical variable to control the flow.
This is some of the work we plan for the future. Compiler experts will note that while LTO can do the global dataflow analysis, it is not in a part of the compiler that prints out syntactic error messages (the same is true of Clang/LLVM). At my FOSDEM 2017 talk, some of the audience pointed out that perhaps full LTO is not needed; possibly build-time attributes, as found in ARM LLVM, might be sufficient.
In summary, critical variable analysis is easy for simple cases, but anything in the real world will need dataflow analysis of some sort to get a whole program view.
What if we get it wrong?
It is very unlikely that we can spot all cases of critical variables controlling flow. Since the analysis depends on dataflow, anything that disrupts dataflow analysis (such as library calls, inline assembler, or assembly code functions), will lead to an incomplete analysis.
False positives mean a lot of fruitless debugging trying to find a problem that is not there. Such wasted effort is certain to reduce confidence in the technique. Conversely, false negatives mean some “bad” code will get through. On the whole this is a better scenario. At present, there is no such automated analysis and even spotting some of the bad cases (and hopefully quite a few) is a big improvement. So our initial implementations will err on the side of caution and we won’t report a critical variable control problem unless we are certain.
There are those who argue that for the most critical code — i.e. where lives are at risk — then maybe we should live with false positives. I think in such a scenario, it would be important for the compiler to print out a full diagnostic analysis, to ensure the programmer can quickly consider all the possible causes and determine if the compiler has flagged a false alarm.
A final thought on critical variables:
I’ve only considered control flow as a way of leaking information. However, even individual instructions can leak information. The following heat map, created by Dr James Pallister when he was at Bristol University, shows how much energy is consumed by an 8-bit multiply instruction for a popular microprocessor:
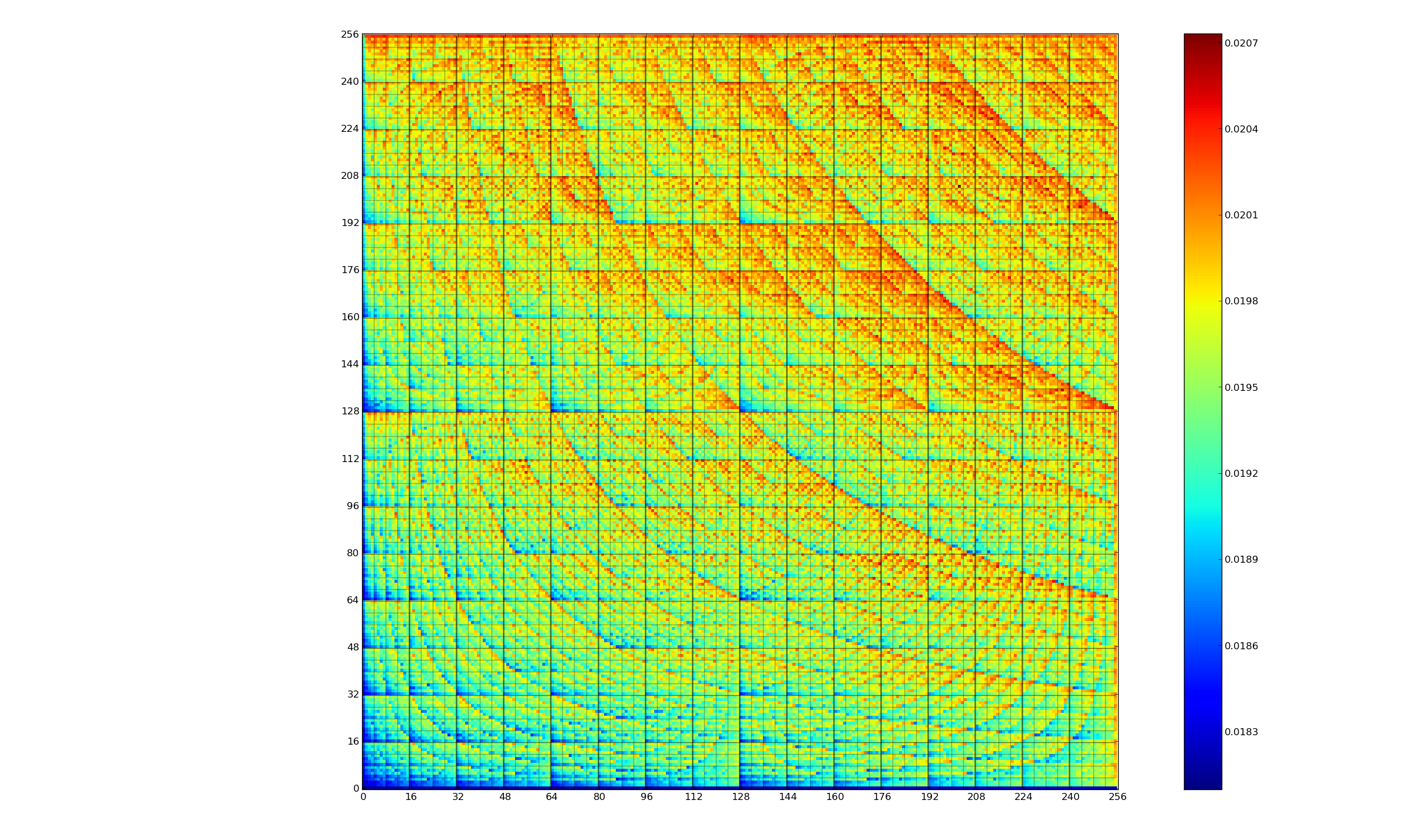
Measuring the energy will give a very good idea of likely pairs of numbers being multiplied.
Automated Bit Splitting
One approach to finding the values of critical variables is to slice the top off a silicon chip and watch it under a scanning electron microscope as it operates. It is relatively easy to read out the memory using such an approach. If, say, a 32-bit cryptographic key is stored in memory, then all 32-bit values are good candidates for that key. The solution is to split such values up and store each part in different locations. As a simple example we could split into four 8-bit bytes and have the linker store each in a different location. The challenge is then that any operation on the split value is much more complicated. For example, to increment such a value we would need the following:
#include <stdint.h> uint8_t k0, k1, k2, k3; void inc_key32 () { k3++; if (0 == k3) { k2++; if (0 == k2) { k1++; if (0 == k1) k0++; } } }
This should work, but there is a danger that a modern compiler would spot the pattern and optimize by combining k0 through k3 into a single 32-bit value, incrementing and storing back, thereby defeating the purpose of never holding the 32-bit value in memory. And this example is just for byte splitting; serious protection requires splitting at the bit level. It is always going to be computationally expensive, but this is code for ultra-secure systems, which are prepared to spend the cycles.
The solution, which we plan to implement for the LADA project, is to let the compiler do the hard work.
#include <stdint.h> uint32_t k __attribute__ ((bitsplit)); void inc_key32 () { k++; }
This is trivial for the programmer, it ensures the compiler does not try to optimize away the security, but does generate the best possible bit-by-bit code. Almost certainly the code would be in an internal library, such as CompilerRT (for Clang/LLVM) or libgcc (for GCC), but the compiler can still ensure that the combined value is never left in memory to be read.
The problem still requires global dataflow analysis, to ensure that the variables are correctly tracked, although unlike critical variables, this will always be correct. We only have to follow successful data flow analyses which lead to optimizations.
The compiler also needs to interact with the linker to ensure that variables are properly scattered across the relevant memory.
Other areas of interest
With critical variables I have shown how we plan to implement one feature that can warn the programmer of dangerous code. With bit splitting I have shown how the compiler can handle the heavy lifting for secure programming. However, there are many other areas we wish to investigate over the coming years.
- Atomicity. Balancing control flow paths
- Superoptimization for minimal information leakage
- Algorithmic chose. Using a range of different algorithms at random to perform the same computation
- Instruction set extensions. We’ll look at how the compiler can be helped by extending the instruction set
- Instruction shuffling. Using flexibility in scheduling code, to make timing, memory access and energy usage less predictable.
In many cases much of what we wish to implement in real compilers has been known in academic circles for years. Our objective is to get that work implemented in real compilers, specifically Clang/LLVM anad GCC, but then to also work closely with our colleagues at Bristol University to push the latest ideas into compilers as quickly as possible.
How you can get involved
- Out work is for open source compilers, so as we contribute code, you can help by reviewing and improving that code. Indeed, you can pick up some of the ideas here are run with them yourself.
- Bristol University is still recruiting research students and academic staff for the LADA project. If this is the job for you, please contact Prof Oswald directly for more information.
- We’ll be keeping the community updated on our work at meetings of the compiler community: EuroLLVM, GNU & LLVM Cauldrons, the LLVM Developer’s meeting and FOSDEM. Please meet us there and contribute your ideas to the project.
- Join the IoT Security Foundation (of which Embecosm is a founder member).
- I’ll be speaking at The IoT London Meetup on 21 February 2017, and I look forward to seeing you there.
And finally of course:
- Talk to Embecosm about how we can deliver this functionality for your compiler.
This post is based on a talk I gave at FOSDEM 2017, updated in the light of the discussion there. My thanks to all who made contributions, whose voices if not names, are preserved for posterity on the video.