RISC-V is an open-source Instruction Set Architecture (ISA) that was originally developed for teaching and research in computer architecture. It is rapidly moving towards becoming a standard architecture for industry applications, with Version 2.0 of the user-level ISA finalised, and a draft specification for the privileged-mode ISA. The base architecture consists of a 32- or 64-bit integer architecture (I) with 32-bit instructions. There are additional extensions for integer multiplication and division (M), atomic instructions (A), floating-point arithmetic (F) and double-precision floating-point (D). A compressed instruction extension (C), featuring 16-bit instructions to reduce code size, is also under development.
On the compiler toolchain side, there are ports of both GCC and LLVM for RISC-V. Both toolchains are actively maintained, and the majority of community effort seems to be focused around the GNU toolchain. Documentation for the various tools is provided at http://riscv.org/software-tools/.
I have been recently been experimenting with the RISC-V compiler toolchains, and this post discusses some first impressions of both GCC and LLVM for RISC-V.
The GNU Toolchain
The RISC-V GNU toolchain consists of GCC, Binutils, newlib and glibc ports. The GCC port is based on GCC 6.1.0 and receives commits on a frequent basis. A script for building the entire toolchain for RISC-V 64 is provided within the toolchain repository, but it is also straightforward to build the toolchain outside of it using this script, and no issues were encountered during the build. Once the toolchain was built, it was possible to compile all of the RISC-V ISA tests from the RISC-V tools repository and execute these on riscv-qemu.
Although the build scripts and documentation focuses on building the toolchain for RISC-V 64, the GCC port can also be built for RISC-V 32 by appending some additional flags to the configure script. My build for RISC-V 32 used:
configure --xlen=32 --with-arch=ICThe --xlen=32 flag sets the register width, and the --with-arch flag can be used to specify the base ISA that the toolchain is built for — this defaults to IMAFD, but I chose to build for the base integer architecture with the compressed instruction extension only.
Once I’d built the GNU toolchains for both RISC-V 32 and 64, compiling the ISA tests for RISC-V 64 and running them on riscv-qemu was a straightforward process. My own runs of the ISA tests for RISC-V 32 are still a work-in-progress.
The LLVM toolchain
The LLVM toolchain port for RISC-V began whilst LLVM 3.3 was current and one port that is based on LLVM 3.3 is provided as a stable release. However, the 3.3 release is quite old at this point, so there is also another branch tracking LLVM master, which has commits from master merged in occasionally, with the most recent merge having taken place in January 2016.
It is documented that using Clang and LLVM to compile RISC-V code requires the use of the GNU toolchain assembler and linker, which is not uncommon and this is also required on several other architectures. The documentation for RISC-V LLVM suggests that a compilation using Clang must be invoked in two stages: one to generate an assembly file using Clang, and another to use the GNU toolchain to assemble and link. This can be a little fiddly if you have a build system that you don’t want to modify for this two-step process, but it turns out that it is possible to invoke Clang such that it can call the GNU toolchain for assembly and linking. A Clang invocation that does this for 64-bit targets is:
clang -target riscv64-unknown-elf -mriscv=RV64IMAFD -nostdinc-isystem <clang header path> -isystem <GNU header path>
where the Clang header path is the full path to lib/clang/3.8.0/include under the RISC-V LLVM install directory, and the GNU header path is riscv64-unknown-elf/include under the RISC-V GNU toolchain install directory.
Checking out the master branch and compiling it yielded a set of binaries that pass all the RISC-V specific IR compilation tests, and a subset of other LLVM tests. At this point I’ve had mixed results with Clang-compiled C code — some compiled programs segfault at certain points during execution, whilst others do work.
Compiling C programs for RISC-V 32 is also possible by substituting in the flags -target riscv-unknown-elf -mriscv=RV32<arch>. I used RV32IC to match my GNU toolchain build, but RV32IMAFD would be a sensible default choice. In order to get the assemble and link steps working for RISC-V 32, I also created symlinks to all the riscv32-unknown-elf-* tools with the prefix riscv-unknown-elf-*. Otherwise, Clang would not find these tools due to their prefixes not quite matching the target name.
Comparing Code Size between GCC and LLVM for RISC-V
As an experiment prior to having a full benchmarking and testing environment set up for runtime comparison with other architectures (such as ARMv7/8 and x86_64), I carried out a short investigation of the code size of RISC-V binaries. To set up the benchmark, a subset of the MiBench benchmarks were selected: those with relatively straightforward build processes were chosen, as it can be quite time-consuming to get some of the more complex builds working with a variety of cross-compiling toolchains. Each benchmark was compiled using each of the toolchains under evaluation, with individual object files and linked executables produced as output. The -Os flag was used to instruct the compiler to optimise for code size. The code size for a given object is measured as the sum of the sizes of all text sections in the object. For full details of the compiler flags and setup used, or to reproduce the benchmark in the context of your own setup, see the Github repository.
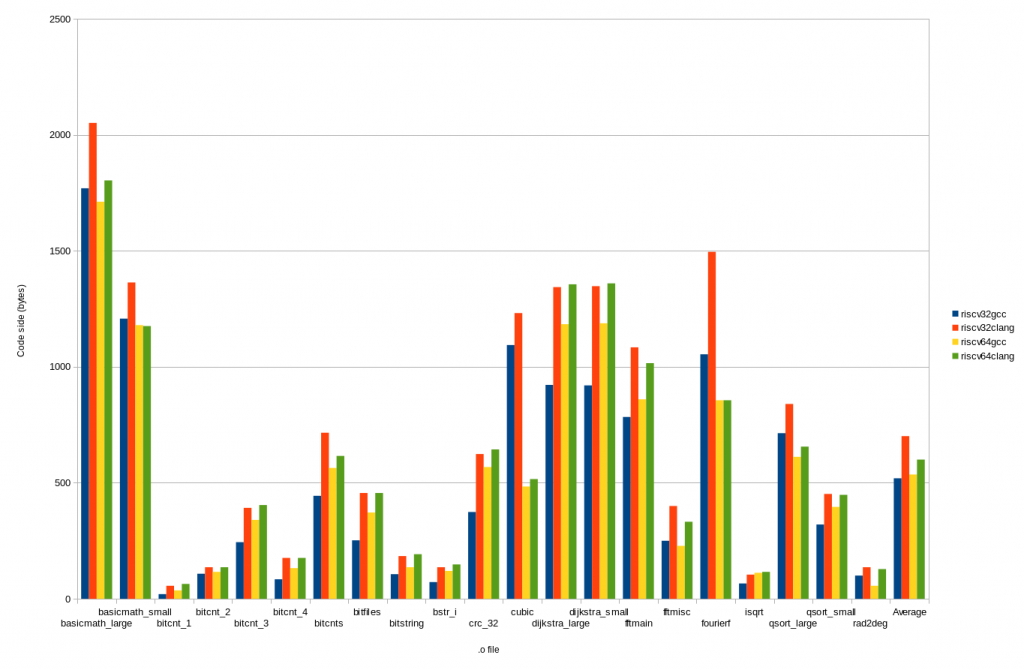
Using the RISC-V compiler toolchains (GNU toolchain revision 7b87222 for RISC-V 64, GNU toolchain revision 728afcd for RISC-V 32, and LLVM revision edb9fec for both 32 and 64) to compile the benchmarks results in a set of objects with the sizes given in the following figure (click to enlarge):
 The average shown above is the arithmetic mean of the code size for all objects. The average for each of the architectures in bytes, and relative to RISC-V 32 GCC, are also shown in the following table:
The average shown above is the arithmetic mean of the code size for all objects. The average for each of the architectures in bytes, and relative to RISC-V 32 GCC, are also shown in the following table:
| RISC-V 32 | RISC-V 64 | |
| GCC | 519 bytes (100%) | 536 bytes (103%) |
| Clang/LLVM | 701 bytes (135%) | 600 bytes (116%) |
On average, GCC produces fairly similar code sizes for both RISC-V 32 and 64. Clang-generated code is a little larger, particularly for RISC-V 32, whose code size is actually larger than for RISC-V 64. As the GCC output demonstrates, it is possible for the RISC-V 32 code to be smaller than the RISC-V 64 equivalent, so this is something that could be expected to be resolved over time and with further development.
Comparing Code Size Between RISC-V and ARM
To compare RISC-V with some similar architectures, the benchmarks were also built for ARMv7m, ARMv8m and ARMv8a using GCC ARM Embedded version 2016q1. The code sizes for objects produced by GCC for each of these architectures is shown below:
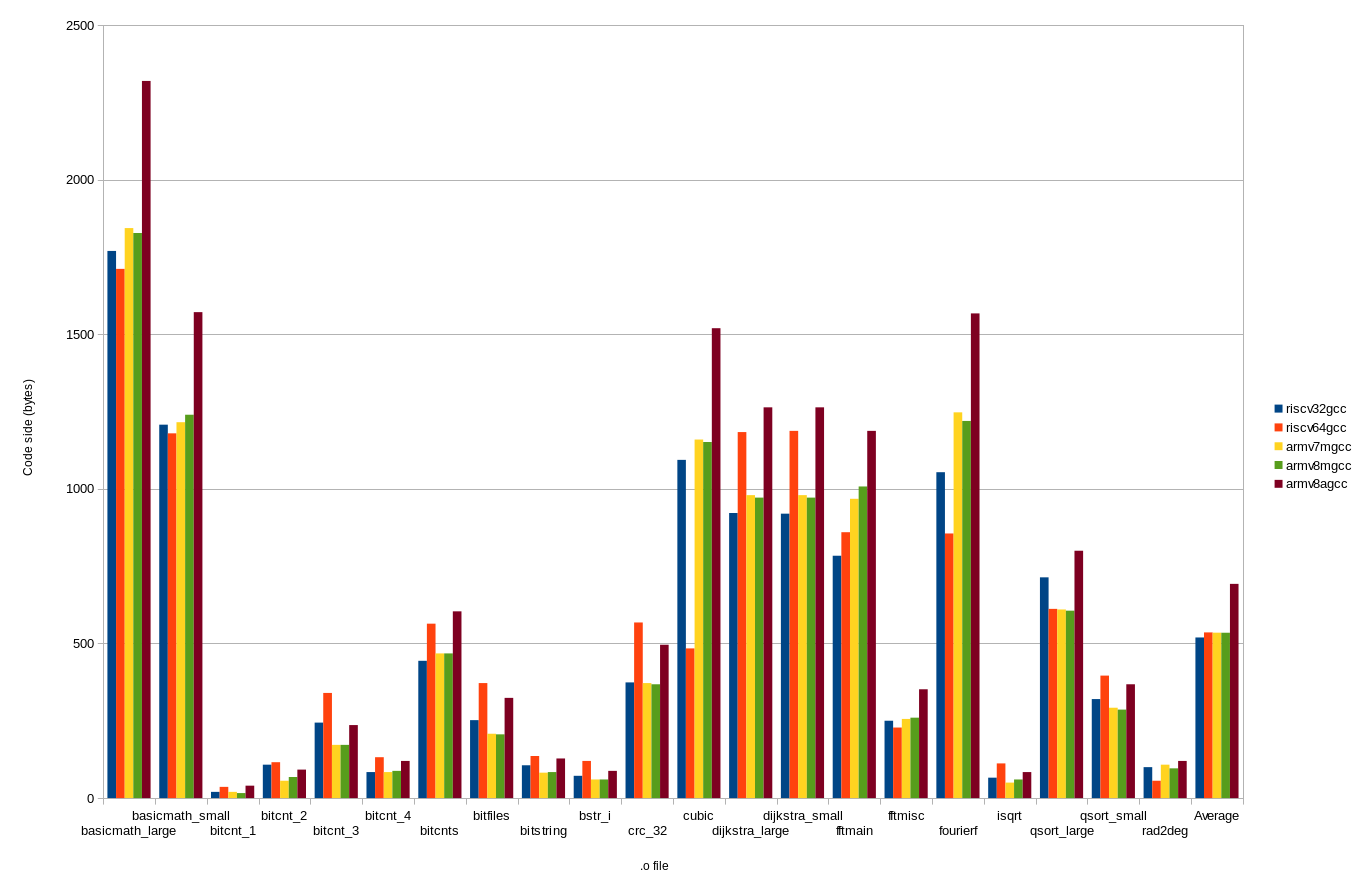
Average values (again the arithmetic mean) are shown in the table below:
| Architecture | Average code size |
| RISC-V 32 | 519 bytes |
| RISC-V 64 | 536 bytes |
| ARMv7m | 535 bytes |
| ARMv8m | 535 bytes |
| ARMv8a | 693 bytes |
On average, code size is very similar between RISVC-V 32/64 and ARMv7m/ARMv8m, with RISC-V 32 code being slightly smaller than the other architectures.
Executing Compiled Code
There are three options for executing RISC-V code:
- Spike, the RISC-V ISA simulator
- The QEMU RISC-V port, which can bring up a whole Linux system
- ANGEL, a Javascript RISC-V simulator
Although I have yet to perform execution measurements for any of the benchmarks, it is worth noting that Spike allows execution of the compiled benchmark code. An example invoking the Bitcount benchmark:
$ spike pk bitcnts.riscv64gcc 100 Bit counter algorithm benchmark Optimized 1 bit/loop counter > Time: 0.000 sec.; Bits: 1585 Ratko's mystery algorithm > Time: 0.000 sec.; Bits: 1260 Recursive bit count by nybbles > Time: 0.000 sec.; Bits: 1905 Non-recursive bit count by nybbles > Time: 0.000 sec.; Bits: 1341 Non-recursive bit count by bytes (BW) > Time: 0.000 sec.; Bits: 1398 Non-recursive bit count by bytes (AR) > Time: 0.000 sec.; Bits: 1592 Shift and count bits > Time: 0.000 sec.; Bits: 1359 Best > Optimized 1 bit/loop counter Worst > Optimized 1 bit/loop counter
Conclusions
At present, the GCC toolchain for RISC-V produces code that is on average 18% smaller than the code produced by the LLVM toolchain for a subset of the MiBench benchmarks. For that same set of benchmarks, RISC-V 64 code is equal in size to ARMv7m and ARMv8m code. RISC-V 32 code is approximately 3% smaller than RISC-V 64, ARMv7m and ARMv8m code.
In a future blog post, I’ll be looking at execution performance by measuring cycle counts for various benchmarks in a simulated environment in order to get some insight into RISC-V performance.
Dr Graham Markall is a member of Embecosm’s GNU compiler development team.