
Summary
- Numba can be modified to run on PyPy with a set of small changes. With these changes, 91.5% of Numba tests pass.
- Execution speed appears to be similar to using Numba on CPython, with a small overhead.
Introduction
I recently attended the LLVM Cauldron to give a talk, Accelerating Python code with Numba and LLVM (slides, video).
At the Cauldron, I met Manuel Jacob, a PyPy developer, who told me about recent work on cpyext, and encouraged me to try porting Numba to PyPy. I was not optimistic about succeeding in doing so because Numba uses a lot of the CPython C API — including some undocumented functions and access to raw struct data — but I thought it was worth trying to assess how big the problem of running Numba on PyPy is, and what would need to be done to make it work.
To my surprise, it turns out that it is possible to make the majority of Numba functionality work correctly on PyPy. I did this in collaboration with Manuel, who provided a wealth of PyPy and cpyext expertise. The rest of this post discusses:
- What had to be done to make it work;
- Current functional test results;
- Some very early performance indications;
- Next steps for the future – how to improve on the work so far; and
- Directions for setting up and environment with Numba and PyPy for your own testing / experiments.
Modifying Numba to work on PyPy
This section contains technical details about the changes made to Numba to run on PyPy. If you’re not interested in these details and are interested in the test coverage and performance measurements, skip ahead to the next section.
Although Python packages that use C extensions have not worked well with PyPy in the past, support for them is now much improved. The effort to support running the official distribution of Numpy — rather than NumPyPy, a version of NumPy with the C extension parts rewritten in RPython — has greatly increased the support for the CPython C API, that PyPy’s cpyext provides. cpyext is now advanced to the point where a lot of C Extension modules will work with minimal or no changes.
With Numba making use of C Extensions, both through the official API and also using some undocumented parts of CPython and some “tricks”, I was prepared for a rough ride. However, it turns out that with a few days’ effort and some relatively simple (in the context of what is being attempted) changes, it is possible to get Numba to compile and run on PyPy. Although it is possible to execute the majority of jitted code on PyPy, and many tests pass, the pass rate is not yet at 100%. Some things don’t work as expected for unclear reasons, and some features have to be disabled (such as the extra profiling support) for the time being.
The following subsections detail the changes and workarounds needed to run Numba on PyPy.
Removing call tracing support
The call tracing support (implemented in numba/_dispatcher.c) for enhancing the Python profiler’s view of Numba-compiled code makes use of the internals of Python’s PyThreadState structure, which are not exposed by cpyext. Since the call tracing support is not essential for correct execution, a simple workaround is to comment out the call tracing support entirely.
Swapping the _PyObject_GC_UNTRACK macro
When environments, closures or generators are deallocated, Numba instructs the Python garbage collector not to collect them (in numba/_dynfunc.c). To do this it uses the macro _PyObject_GC_UNTRACK, possibly for performance reasons. However, this macro is not defined in cpyext, so it cannot be used. Instead, cpyext provides the function PyObject_GC_UnTrack which performs the same function, so we can make use of this function instead.
Missing floating-point functions
In numba/_helperlib.c there are various implementations of floating point functions that make use of functions such as Py_IS_NAN, which are macros in CPython, but not defined in cpyext. To work around this, these are #defined at the start of the numba/_helperlib.c and numba/_math_c99.c files that make use of them, like so:
#define Py_MATH_PI 3.14159265358979323846 #define Py_IS_NAN(X) isnan(X) #define Py_IS_FINITE(X) isfinite(X) #define Py_IS_INFINITY(X) isinf(X)
Missing _Py_C_pow function in cpyext
The _Py_C_pow function is used to implement the complex power function for use inside jitted functions. This function is not provided by cpyext, and there is no simple equivalent that can be substituted instead. As the CPython implementation of this function doesn’t call any other API functions that would also need implementing, copying the implementation from the CPython source tree into the Numba source gives a way to provide this function.
Pointer-stuffing in lists
Numba’s mechanism for tracking objects and interacting with the Python garbage collector at the boundaries of jitted functions associates an instance of a meminfo struct (a type internal to Numba) with each object that it tracks inside a jitted function. This tracking mechanism works for most objects, because Numba internally uses a dict to map objects to meminfo structs, all of which uses API functions supported by cpyext.
However, for associating meminfo structs with lists the implementation is a little different, possibly because lists were the first collection to be supported inside jitted functions, and for which a special hack is applicable: instead of using a separate dict, a pointer to the meminfo struct is stored inside the internals of a PyListObject, in the field named allocated. This works because the allocated field — which records how many items space is allocated for in the list — is not used during the execution of a jitted function. After the jitted function returns, the value of the allocated field is re-computed to be equal to the current size of the list. This makes a small trade-off: no additional data structure is needed for this tracking, but when the associated meminfo struct is finished with and the allocated field reset to the size of the list, a subsequent unnecessary re-allocation may be triggered, in the case where there was more space already allocated than the size of the list.
The cpyext PyListObject implementation has no field called allocated, so this hack doesn’t work. Because the dict-based method for associating meminfo structs with objects does work, the implementation of Numba’s _python_list_to_native and unbox_list functions can be converted to use this method. This was a little tricky because the implementation of these functions did not exactly follow the pattern of the dict-based method, but it was nothing that a little head-scratching and debugging couldn’t resolve.
Missing PyExceptionInstance_Check
The CPython macro PyExceptionInstance_Check is not implemented in cpyext. Copying the implementation straight from CPython does not work, because the macro uses some of the internal implementation details of CPython objects. Instead, a reimplementation of this for PyPy was written (inside numba/_helperlib.c) which makes used of the PyInstance_Check and PyObject_IsSubclass functions, which are provided by cpyext.
This reimplementation appears to mostly work; however, it may be responsible for some unexpected failures/errors and may require further debugging.
Re-raising exceptions uses PyThreadState internals
Numba supports re-raising exceptions in jitted functions. For example, this occurs when a jitted function is called during exception handling, like:
@jit
def f():
raise
try:
raise AttributeError("err")
except AttributeError:
f()
The implementation behind this is in numba_do_raise in numba/_helperlib.c. The implementation of this function appears to be inspired by the do_raise function in CPython, which gets the current thread state with PyThreadState_GET(), then it looks at its exc_type, exc_value and exc_tb values and sets them as the current exception by using PyErr_Restore. Unfortunately, the cpyext thread state does not have these fields, so a similar implementation was not possible.
My first attempt involved getting the equivalent information using the PyErr_GetExcInfo function provided by cpyext. This is actually a C API function that was originally a Cython extension and is part of the CPython 3 C API. Fortunately, cpyext implements it even for Python 2 in PyPy. This worked to some extent – the re-raising occurred, but the topmost frame is always lost in the traceback, for reasons unknown. I could not see a simple fix for this.
The second attempt, based on a suggestion by Armin Rigo in the #pypy IRC channel, is to implement the re-raising using only PyRun_SimpleString("raise"). This feels a little bit “hacky” but it actually works correctly!
Missing _PySet_NextEntry
_PySet_NextEntry is a CPython macro for iterating over sets which is not implemented in cpyext. However, in Numba it is only used to determine if a set is empty, with a check like:
if (!_PySet_NextEntry(val, &pos, &item, &h))
The PySet_GET_SIZE function is supported in cpyext, so we can re-write this check as:
if (PySet_GET_SIZE(val) == 0)
Bytecode differences
Upon inspection, it appears that PyPy and CPython seem to use slightly different bytecodes for method calls (I have not looked into the reasons underlying this so far).
- In CPython, a method call seems to consist of an attr lookup a function call.
- In PyPy, a method call consists of a lookup of a method and then a call of the method.
This causes a problem for Numba’s Bytecode Interpretation stage. No fundamental changes are required, but the difference is worked around by adding the PyPy bytecodes CALL_METHOD and LOOKUP_METHOD to the bytecode tables in Numba. The rest of the implementation of Bytecode Interpretation — and also Dataflow Analysis — for these bytecodes is then shared with the CALL_FUNCTION and LOOKUP_ATTR bytecodes.
Function Naming
CPython API functions are generally prefixed with Py. In cpyext, the symbols for the equivalent functions have the same name, but with the prefix PyPy. For example, PyExc_SystemError becomes PyPyExc_SystemError. In normal use this is not an issue, since cpyext defines macros to alias names that have the prefix PyPy with the names prefixed with only Py when compiling a C extension. However, Numba uses the symbol table to locate some of these functions when linking jitted code, which causes an issue because the symbol table doesn’t contain macros.
In order to work around this issue, all references to functions that are looked up in the symbol table and begin with Py are modified to begin with PyPy instead. Most of these references exist in numba/pythonapi.py.
Additional symbols added by Numba
Not all functions required by jitted code are exported by CPython. Some (such as some exceptions, and _Py_NoneStruct) are required, but not exported. In order to work around this — in numba/targets/base.py — Numba looks up the address of these symbols from python using the id function, then adds them to the symbol table.
It makes no sense to use id to get the address of an object in PyPy, because the fact that the ID is the underlying pointer is an implementation detail of CPython, rather than something that can be expected in any Python interpreter. By fortunate coincidence, all of the symbols that are required by Numba are already in the symbol table in PyPy, so the workaround for this particular problem is simply to comment out the code which looks up the ID of objects and adds them to the symbol table.
ctypes.pythonapi support in PyPy
Some of Numba’s testing uses ctypes.pythonapi (for example, those in in tests/ctypes_usecases.py) in its tests of ctypes support. ctypes.pythonapi presently appears not to be provided in PyPy. Since ctypes support can be seen as a small corner of Numba’s functionality, for the purpose of getting through the test suite, the offending test code has been commented out.
Missing tuple.__itemsize__ on PyPy
Numba uses tuple.__itemsize__ in various places (e.g. numba/config.py, numba/cuda/cudadrv/nvvm.py) in order to determine whether it is running on a 32- or 64-bit machine. For a simple workaround, all instances of tuple.__itemsize__ have been replaced with a hardcoded value of 8 in order to avoid determining how to detect the bit width, since the majority of users (myself included) will be running on 64-bit machines.
Summary of test results
Executing pypy runtests.py -v (with PyPy 5.4.1 on Linux and commit a26484a of my PyPy Numba branch) results in the following summary at the end of execution:
Ran 6472 tests in 829.757s FAILED (failures=28, errors=304, skipped=317, expected failures=5)
Some thoughts and notes on the above:
- 91.5% of Numba tests are passing, covering the majority of Numba’s functionality;
- Don’t read too much into the execution time of the test framework, which was executed single-threaded on my old laptop whilst I was doing other things. See the next section for performance indications instead;
- Some skipped tests are CUDA tests;
- Other tests have been marked as skipped on PyPy, either because of unsupported functionality that crashes the test suite or interpreter, or simply taking too long to run (possibly stuck in infinite loops);
- The failures are things that didn’t work, but didn’t crash the interpreter or test suite so I left them to execute.
Performance measurements
This section contains some preliminary performance measurements, using the example solutions that I usually use as part of giving a Numba tutorial — the source of these can be found here. The four configurations are:
- CPython only (i.e. the original code running on CPython)
- CPython + Numba (the example solution for each problem running on CPython)
- PyPy only (the original code running on PyPy with Numpy + cpyext)
- PyPy + Numba (the example solution for each problem running on PyPy)
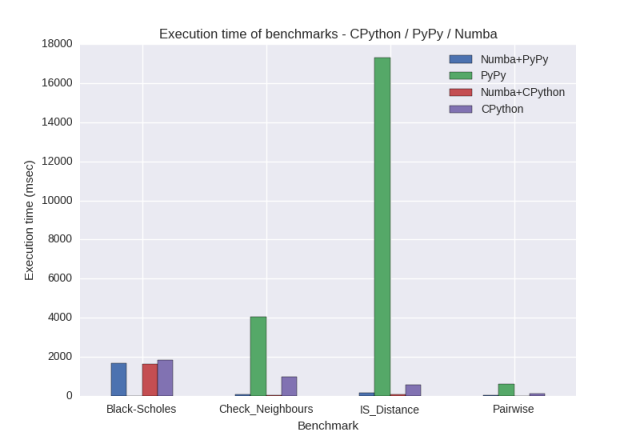
The PyPy-only execution times are relatively large, and this is likely to be due to the overhead of cpyext with Numpy for relatively small workloads. It is clear from these results that the above benchmarks do not necessarily provide a good representation of the differences between PyPy, CPython, and Numba etc., so instead we will focus on the difference between using Numba on CPython and Numba on PyPy only.
If we compare the execution times of the Numba benchmarks on CPython and PyPy only, we see:
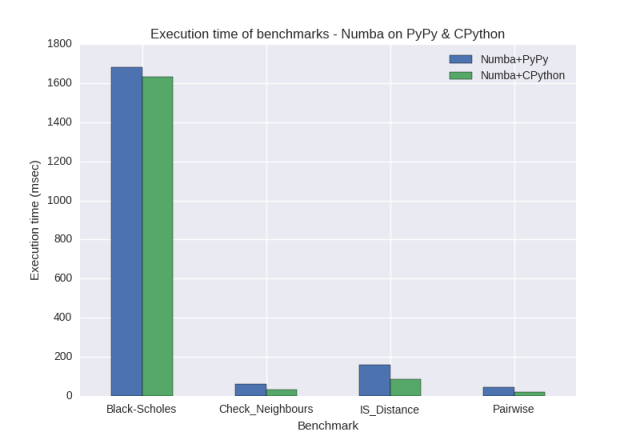
The execution times suggest that there is a small overhead when using Numba on PyPy compared to on CPython, since the execution times of the benchmarks all differ by approximately the same amount of time. For large applications, I would expect that this overhead would be amortised entirely (noting that the overhead is only a small percentage of the execution time for the longest-running benchmark, Black-Scholes).
What next?
Although the set of patches described above brings a large chunk of Numba functionality to PyPy, there is still work to be done to bring the current implementation into a production-ready state. Issues that need addressing include:
- Bring the test pass rate to 100%: although it may be acceptable to leave some functionality unsupported (and tests skipped) on PyPy, a finished patch set should not result in any errors or failures;
- Compatibility of patches: the present patch set almost certainly breaks support for CPython. Most of the changes made would need to be conditionally enabled depending on whether the build is for PyPy or CPython in order to keep the code compatible with both CPython and PyPy.
Whether it’s worth pursuing the goal of providing proper support for PyPy in Numba depends on whether there would be sufficient interest in it, and the potential maintenance burden for the team maintaining Numba. I would welcome comments and feedback from Numba users and developers — please feel free to use the comments section to give feedback, and if you have tried out the branch for PyPy support, to post any measurements/timings that you make.
Trying out the PyPy port
To try out this port, the following needs to be set up:
- PyPy. I used PyPy 5.4.1, which was the current version at the time of this work. I followed the instructions in the “Installing” and “Installing Numpy via cpyext” sections in http://pypy.org/download.html.
- llvmlite. I used revision e924ffa from https://github.com/numba/llvmlite and installed with
pypy setup.py install. If you run the tests you will find a small number of failures on PyPy, but this did not prevent the results above being obtained. - Numba: Use revision a26484a from https://github.com/gmarkall/numba/tree/pypy and build with
pypy setup.py build_ext --inplace, then add to yourPYTHONPATH(or install it withsetup.py install, if you prefer).
Afterwards, you should be able to run import numba in PyPy and use it as normal, or run the test suite.