An Altruistic Processor (AAP) is an architecture specification designed for experimenting with compiler back end implementation. In particular it has features that are common within small deeply embedded systems. It is also designed to be easy to use in demonstrations and for education/training, with hardware and simulator implementations as well as the tool chain and standard libraries.
 The design is based on no processor in particular, although as an open hardware design, it is inspired by the OpenRISC and RISC-V projects. There are features drawn from a wide range of processors developed over the past 30 years. Indeed the branch-and-link operation goes back even further, to the IBM 360.
The design is based on no processor in particular, although as an open hardware design, it is inspired by the OpenRISC and RISC-V projects. There are features drawn from a wide range of processors developed over the past 30 years. Indeed the branch-and-link operation goes back even further, to the IBM 360.
A particular objective is to improve LLVM for deeply embedded systems. At present the official LLVM distribution has only one of its 12 officially supported architectures, the MSP360, that is not a 32- or 64-bit design. But even the MSP430 is a RISC architecture, with a uniform address space, and its LLVM implementation still has experimental status.
Once the entire AAP tool chain is complete, we plan to submit it for adoption in the official LLVM distribution.
Features
These are the key features of the AAP design.
- 16-bit RISC architecture. The core design sticks to the RISC principles of 3-address register-to-register operation, a small number of operations and a simple to implement datapath. The fundamental data type is the 16-bit integer.
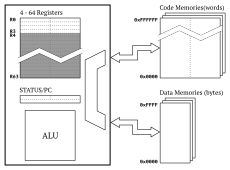
- Configurable number of registers. Although 32/64-bit RISC architectures typically have 16 or more general purpose registers, small deeply embedded processors often have far fewer. This represents a significant compiler implementation challenge. To allow exploration of this area, AAP can be configured with between 4 and 64, 16-bit registers.
- Harvard memory layout. The basic architecture provides a 64k byte addressed data memory and a separate 16M word instruction memory. By requiring more than 16-bits to address the instruction memory, the compiler writer can explore the challenge of pointers which are larger than the native integer type. Deeply embedded systems often have very small memories, particularly for data,
so the size of memories can be configured. - Multiple address spaces. Many architectures also provide more than two address spaces, often for special purposes. For example a small EEPROM alongside Flash memory, or the Special Purpose Register block of OpenRISC. AAP can support additional address spaces, allowing support for multiple address spaces throughout the tool chain to be explored.
- 24-bit program counter with 8-bit status register. AAP requires a 24-bit program counter, which is held in a 32-bit register. The top bits of the program counter then form a status register. Jump instructions ignore these top 8 bits. At present only one status bit is defined, a carry flag to allow multiple precision arithmetic.
- 16/32-bit instruction encoding. A frequent feature of many architectures is to provide a subset of the most commonly used parts of the Instruction Set Architecutre (ISA) in a short encoding of 16-bits. Less common instructions are then encoded in 32-bits. Optimizing to use these shorter instructions, is particularly important for compilers for embedded targets, where memory is at a premium. AAP provides such a 16-bit subset with a 32-bit encoding of the full ISA. However it
follows the instruction chaining of RISC-V, so even longer instructions could be created in the future. - Three address code. AAP has stuck rigidly to the RISC principle of 3-address instructions throughout. Almost all instructions come in two variants, one where the third argument is a register, and one where the third argument is a constant.
- No flags for flow of control. There are no flag registers indicating the results of operations for use in conditional jumps. Instead the operation is encoded within the jump instruction itself. There is an 8-bit status register as part of the program counter, which includes a carry flag. However this is not used for flow-of-control, but to enable mutliple precision arithmetic.
- Little endian. The architecture is little-endian—the least significant byte of a word or double word is at the lowest address. The behavior for instruction memory is that one word is fetched, since it may be a 16-bit instruction. If a second word is needed, then its fields are paired with the first instructions to give larger values for each field. This is done in little-endian fashion, i.e. the field from the second instruction forms the most significant bits of the combined field.
- No delay slots. Early RISC designs introduced the concept of a delay slot after branches. This avoided pipeline delays in branch processing. Implementations can now avoid such pipeline delay, so like most modern architectures, AAP does not have delay slots.
- NOP with argument for simulator control. This idea is taken from OpenRISC. The NOP opcode includes fields to specify a register and a constant. These can be used in both hardware and simulation to trigger side-effects.
Next steps
Today we publish the outline architecture specification as Embecosm Application Note 13. Over the coming weeks we will be releasing a simulator for the architecture and all the components for the full LLVM tool chain. We’ll be talking about those components here. Our final goal is to release a FPGA hardware implementation.
When we are satisfied that the tool chain components are of high quality, we will be submitting them upstream. However they’ll be freely available before then on the Embecosm GitHub pages.