Benchmarking is important in the embedded world, where we need to know whether applications will meet their real-time constraints, how much resources they use and power they consume. For my work on the energy consumption of compiler options, I constructed a set of benchmarks that had certain desirable characteristics for measuring energy consumption. In this blog post I will talk about how I selected the benchmarks and particular features they have, which allows a comprehensive overview of an embedded processor’s energy consumption.
Benchmarks for Energy?
Software drives the hardware, and as such has a huge impact on how much energy is needed to do a certain calculation – choosing a better algorithm in your application will make it faster and consume less energy. With the software controlling what the hardware does, a benchmark or set of benchmarks is needed to exercise typical use-cases of the hardware, benchmarking how much energy is needed to perform a set of operations. Most of the time just focussing on performance is good enough – if your application runs quicker, it is likely to use less energy overall. However to squeeze out that last bit of efficiency, working out where the energy is used is vital.
A recent article on EDN highlights the difficulties in measuring the power consumption for battery-powered devices – I/O, power states, peripherals and software make it challenging to benchmark energy consumption. For these benchmarks I focussed on the power consumption of the processor, since this is the area where compiler optimisations will have the largest effect.
Another Benchmark Suite
Almost all benchmark suites require some sort of operating system underneath them. This poses a problem for two reasons: In deeply embedded system we often have no operating system, and when profiling energy usage the operating system can greatly obfuscate the results, scheduling threads at inopportune times and the overhead of system management.
Some suites, such as MiBench have benchmarks that could be run bare metal – these were considered and around half of the final benchmark suite is derived from MiBench. The other benchmarks are derived from the WCET collection. MiBench is aimed at embedded systems which run Linux, whereas the WCET benchmarks are a collection of standalone programs, of which most will compile without external dependencies on hardware or software.
Benchmark Characteristics
The intention of this benchmark suite was to exercise different parts of the processor’s pipeline, since the energy consumption in a processor come from active functional units, the registers file and buses connecting the components.
This leads to four orthogonal categories the benchmarks should span across:
- Integer operations
- Floating point operations
- Memory accesses
- Branching
By choosing benchmarks with differing amounts of these operations, different parts of the processor will be activated in different combinations, allowing a full picture of the energy consumption to be obtained. A fifth characteristic, threading, was identified as another aspect that should be considered, using any interconnect and allow the impact on energy from parallel processing to be seen. This is something that should be considered in the future as more compiler optimisations start to impact parallel processing.
The Benchmarks
Initially 20 benchmarks were chosen to cover all of these points. This was later reduced to ten – many of the original benchmarks had similar characteristics, even if they were performing different calculations, reducing the amount of testing that needed to be performed. These formed a minimal set covering a range of different applications while exhibiting a large amount of differing behavior. These benchmarks, with the categories and types of computation they perform are shown below. This list covers many things that embedded systems may wish to do, such as cryptography, networking and mathematical operations.
| Name | Source | License | Int | Float | Memory | Branch |
| Blowfish | MiBench | GPL | High | Low | Med | Low |
| CRC32 | MiBench | GPL | High | Low | Low | Med |
| Cubic | MiBench | GPL | High | Low | Med | Low |
| Dijkstra | MiBench | GPL | High | Low | Low | Med |
| FDCT | WCET | None | Low | High | High | High |
| Float Matrix Multiplication | WCET | None | Med | Med | High | Med |
| Int Matrix Multiplication | WCET | None | High | Low | Med | Med |
| Rijndael | MiBench | GPL | Med | Low | Low | High |
| SHA | MiBench | GPL | Med | Low | Med | High |
| 2D FIR | WCET | None | Low | High | Med | High |
These benchmarks were compiled and run on simulators, gathering statistics about how frequently each instruction was executed. This was repeated for three different processor architectures – ARM (Cortex-M0), Epiphany and XMOS – to check that a similar distribution was obtained for each. The instruction distribution for the benchmarks ran on Epiphany are shown below. The other graphs are not shown here – XMOS and ARM.
{kind=link}
{kind=link}
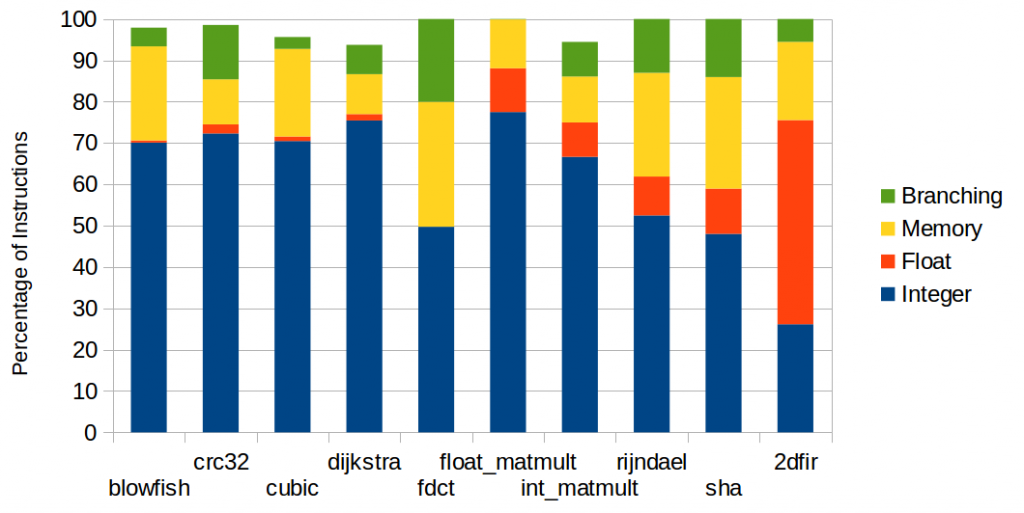
These instructions have been grouped into the above categories and show that types of instructions are roughly as expected and have a good variety of combinations. Not all bars reach 100%, as there are some control instructions not counted. Also some instructions appear as floating point, when they are in reality integer instructions – this comes from the ability of the Epiphany chip to use its floating point pipeline as an integer pipeline.
An interesting point – although perhaps not surprising – is the proportion of integer instructions in every benchmark: above 45% in all but one benchmark. This is a side effect of integers being required for most calculations. Address calculation, bitwise operations, loading constants, manipulating control flow all use integer instructions. The categories are broken down into more detail below.
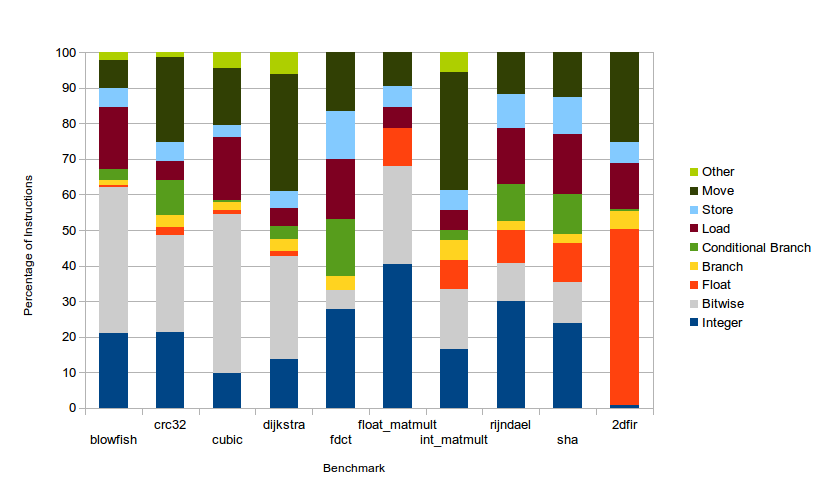
In this more detailed breakdown it can be seen that the integer category breaks down into purely integer (consisting of the arithmetic instructions) and bitwise (consisting of bitwise operations and shifts). In benchmarks such as blowfish and CRC32, a large amount of bitwise operations are performed, as expected. However in Cubic (a cubic root solver), an unexpectedly large amount of bitwise operations are performed. This is because the benchmark uses double precision for the computation, and the Epiphany chip only has single precision hardware. GCC notices this and inserts function calls to emulate the double precision. This emulation typically involves a large amount of bitwise operations, to manipulate the floating point format (the code for GCC’s soft float library can be found here).
One other point of interest is the large proportion of move-type instructions. These occur frequently because Epiphany’s instruction set includes many conditional moves, often negating the need for branches.
Limitations
- None of the benchmarks involve any parallelism.
- All of these benchmarks were chosen to exercise the processor. Therefore no I/O or peripherals are tested. As these can form a significant proportion of the energy consumption in modern processors, benchmarks which include peripheral tests would be needed for a complete system level view of the energy consumption.
- These are targeted at simple, deeply embedded processors. More complex processors with cache hierarchies or superscalar execution may need different categories to fully exercise the processor.
Links
- The benchmarks are on GitHub.
- The list of benchmarks evaluated to choose these is on the project wiki.
- These benchmarks were used in: Compiler optimisations for energy efficiency.
James Pallister is a PhD student in the Department of Computer Science at Bristol University. He is currently doing a HiPEAC internship with Embecosm and contributes to our research into the impact of compilers on energy consumption in embedded systems.