Introduction
One of the currently proposed draft ISA extensions for RISC-V is the Bit Manipulation Instructions extension (from henceonwards referred to as the “Bitmanip” or “BMI” extension.) It proposes to provide fast and direct instructions for commonly-used bitwise operations, often found in cryptographic, logarithmic, bit-counting, and logical operations. The GCC toolchain work has been developed by the community with contributions from SiFive and myself at Embecosm, providing bug fixes, regression tests, and benchmarks.
The specification proposes 95 new instructions (including all variants) spread across 9 subclasses, some of them overlapping. These are organised as shown in the following figure.
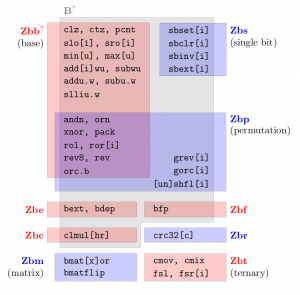
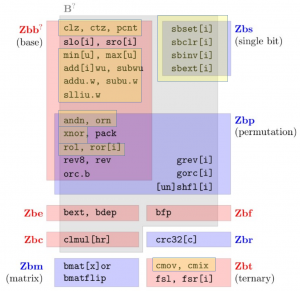
Quick Start
This section will focus on providing the reader with guidance to quickly get started with a Bitmanip compiler. At a minimum, you will need to build a stage-1 GCC and Binutils from source. Optionally, you may also want to build stage-2. The repository for the GCC and Binutils branches may be found here:
GCC: Checkout branch “riscv-bitmanip”: https://github.com/embecosm/riscv-gcc
Binutils: Checkout branch “riscv-bitmanip”: https://github.com/embecosm/riscv-binutils-gdb
Below is an example test program that should give you different results upon enabling Bitmanip
instructions.
#include <stdint.h> enum E { E0, E1, E2, E3 }; #define SOME_STATUS (1ULL << 50) #define ANOTHER_STATUS (1ULL << 58) void f (enum E e, uint64_t *v) { switch (e) { case E0: *v |= SOME_STATUS; break; case E1: case E2: case E3: *v |= ANOTHER_STATUS; break; } }
Compiled with riscv64-unknown-elf-gcc -march=rv32imafdcb_zbb -O2 -S -o test.s test.c, the assembly should look as follows:
f: f: beq a0,zero,.L2 beq a0,zero,.L2 addiw a0,a0,-1 addiw a0,a0,-1 li a5,2 li a5,2 bgtu a0,a5,.L7 bgtu a0,a5,.L7 ld a5,0(a1) ld a5,0(a1) sbseti a5,a5,58 | li a4,1 > slli a4,a4,58 > or a5,a5,a4 sd a5,0(a1) sd a5,0(a1) ret ret .L2: .L2: ld a5,0(a1) ld a5,0(a1) sbseti a5,a5,50 | li a4,1 > slli a4,a4,50 > or a5,a5,a4 sd a5,0(a1) sd a5,0(a1) ret ret .L7: .L7: ret ret
This particular example demonstrates the usage of the sbset instruction, which is used to set a particular bit index to one.
Code Generation
As previously mentioned, not all of the new Bitmanip instructions are known to the RTL backend. This section will focus on those that are, and demonstrates the typical code cases for which they may be selected.
Direct instruction generation
GCC has naitive support for some bit counting instructions. Native in this context means that GCC intrinsically understands the notion of counting bits, trailing bits and leading bits, such that it has a dedicated named RTL instruction for it. Consequently all that is necessary, is to define an RTL template for it, and GCC will automatically consider it for code generation. From the bitmanip.md backend file:
(define_insn "clzsi2"
[(set (match_operand:SI 0 "register_operand" "=r")
(clz:SI (match_operand:SI 1 "register_operand" "r")))]
"TARGET_ZBB"
{ return TARGET_64BIT ? "clzw\t%0,%1" : "clz\t%0,%1"; }
[(set_attr "type" "bitmanip")])
...
(define_insn "ctzsi2"
[(set (match_operand:SI 0 "register_operand" "=r")
(ctz:SI (match_operand:SI 1 "register_operand" "r")))]
"TARGET_ZBB"
{ return TARGET_64BIT ? "ctzw\t%0,%1" : "ctz\t%0,%1"; }
[(set_attr "type" "bitmanip")])
...
(define_insn "popcountsi2"
[(set (match_operand:SI 0 "register_operand" "=r")
(popcount:SI (match_operand:SI 1 "register_operand" "r")))]
"TARGET_ZBB"
{ return TARGET_64BIT ? "pcntw\t%0,%1" : "pcnt\t%0,%1"; }
[(set_attr "type" "bitmanip")])
Indirect instruction generation
Some instructions are used in context of other operations. One such example is the “grev” instruction (Generalized reverse). A special case of this instruction is to reverse the 16-bit quantities within a register word, which is a direct implementation of one of the GCC generic intrinsic functions, __bswap16. This provides a single instruction implementation to what would otherwise take over 10 instructions.
Another such example is the zero extend operation. Armed with the Bitmanip extension, the GCC backend now has an additional strategy for performing zero-extend operations, using the “pack” instruction. This instruction has the semantics of taking the lower 32-bits of two source register operands, concatenating them together, and storing the result in the destination register. If one were to make the 2nd source register r0, the upper 32 bits of the destination register will be forced to zero.
Finally, the riscv.c generic backend code has also learned some new tricks with the help of Bitmanip. One such example is the loading of constants that happen to be a power of two. Normally, this operation is performed by the “li” psuedo-op, which itself expands to 3 instructions. With Bitmanip, we can simply use “sbseti”, with the index of the bit as an immediate argument.
Benchmarks
In order to quantify the effectiveness of the Bitmanip support implementation in GCC, we used the Embench benchmarking suite for both code size, and code performance measurements.
Code size
One of the primary motivations for the Bitmanip ISA development is to increase code density.

Another example of code size decrease can be found in the GCC runtime support library, libgcc. In particular, the generic soft-float implementation experiences code size decrease mainly thanks to the presence of bitcounting instructions clz, ctz, pcnt, thus permitting the compiler to select fast paths within the implementation.
Runtime performance
To measure runtime performance, we connected the PicoRV32 implementation together with the reference implementation of a Bitmanip ALU, and then ran the Embench testsuite through an instance of GDB, connected to the Embecosm Debug Server, which was itself connected to a verilated model of the above system.

Instruction subset selection
In the introduction, it was mentioned that the BMI extension defines 95 instructions spread across 9 classes. The draft specification goes into further detail as to the motivation behind this, which we will omit here. Instead, this section focuses on the user-facing configurations available.
You may select one or multiple subsets for code generation by simply passing them in alphabetical order, like so:
-march=rv32imc_zbc_zbe -march=rv32imc_zbc_zbf_zbm
You may also select the “default” Bitmanip group which includes zbb, zbc, zbe, zbf, zbp, and zbs (all except zbm, zbr, zbt) by simply passing ‘b’ in the primary architecture string:
-march=rv32imc
So, in order to have the entire bitmanip ISA available, the shortest way to indicate this is as below:
-march=rv32imcb_zbm_zbr_zbt
Note, that the string you pass in for the -march directive will also be passed onto the assembler, which will use it to decide which assembly instructions are legal.
Conclusion
The Bitmanip ISA has a real future in terms of boosting both code performance, and improving code density. There are still several codegen opportunities in the machine description that could be filled in, but otherwise this ISA extension is just waiting for users.